Run A Model On Your Laptop
The simplest possible guide to do this.

Just two months ago, I read that the GPT4 level models are now small enough to run on your laptop. I didn’t try it until January and I was surprised at how easy it has become, even compared to December!
And it really is easy. As in, less than 3 steps and 5 minutes. Which is amazing. You should try it - it’ll give you something fun to do today while you’re waiting for the next good Super Bowl commercial.
So here’s the steps to pull down and run a model on your laptop. But first:
Why should you try this?
It’s a great learning exercise to think about how models work - Models are complicated. “Observation is a passive science. Experimentation is an active science.” — Claude Bernard
DeepSeek - DeepSeek sits in the same category as TikTok for me: I will never use the app or send it any data. But the open source models are pretty amazing, especially getting to observe the Chain of Thought. This is a way to safely use the models without interacting with the Chinese entities in any way.
Appreciate the resources - Depending on how big your machine is and which model you pull, you’ll see words whir across the screen at the rate of various species of turtles while the rest of your computer lags considerably and the fan runs hard. Running a single query session locally gives you an appreciation for the scale of the datacenter firepower supporting the millions of queries happening in realtime.
Ask whatever you want - Some people worry a lot about the info they give these services - be it personal details or code. Run it locally and all your data stays right there. Experiment wildly. There are plenty of other ethical or legal dimensions to this, but for now that’s enough.
Observe the future - Another incredible thing about running a model locally is realizing just how much human data is crystallized into these models. You can ask it about the voyages of an explorer, the history of the eggplant, the spec of the Python language.. it will know them all. This is the majority of human knowledge, compressed into a matrix of numbers that can be analyzed and reconstituted based on your query. That is insane. And progress is accelerating.
There’s also this question of centralization around AI. There’s one world in which we all use a central, controlled service that handles everything. And there’s another where we have the compute available locally and run our own models and do what we want with them. This may end up being one of the few critical debates in the AI space. And so it’s important to understand the differences and consequences of these two worlds.
Run Your Model Locally
Here we go..
Step 1: Download Ollama
Ollama is a simple Desktop app that lets you interact with these models locally. It’s a simple and clean install and gives you an easy way to use the most popular models.
Just head to Ollama and Download their executable.
Congrats, you’re halfway there.
Step 2: Run a model
Ollama has a list of models available, and the base models like Llama and DeepSeek R1 are broken down into parameter counts and other attributes. Larger models need more compute but give better performance. I’m using an M3 Mac Air and I’m getting reasonable performance from DeepSeek’s 14B model. Don’t use the biggest models.. unless you have 64 GB of RAM, they won’t work.
Open the Terminal app (the Terminal app is usually the world of engineers, but don’t worry we’re not doing anything fancy here! Press Command + Spacebar to open Spotlight search, type "Terminal" and press Enter)
Type this command:
ollama run deepseek-r1:14bYou’ll see something like this:

That’s your prompt. You’re ready to go! Yes, that’s it..

Let’s give it a go..

There’s a bit to unpack here..
R1 is a Chain of Thought model, and so everything in the <think> tags is effectively the “internal monologue” of the model. You get to see how it’s coming up with things. This can feel odd for sure.
Sometimes the CoT meanders, doesn’t make sense, or even switches languages, like the example here.
The final answer is after the end of the </think> tag, and you can see this is nicely formatted and looks much more like the types of answers we’re used to seeing from ChatGPT.
Step 3: Use a nicer interface
Most people don’t want to sit in a terminal. And there’s a better answer: Chatbox.
Download Chatbox and install it on your Mac
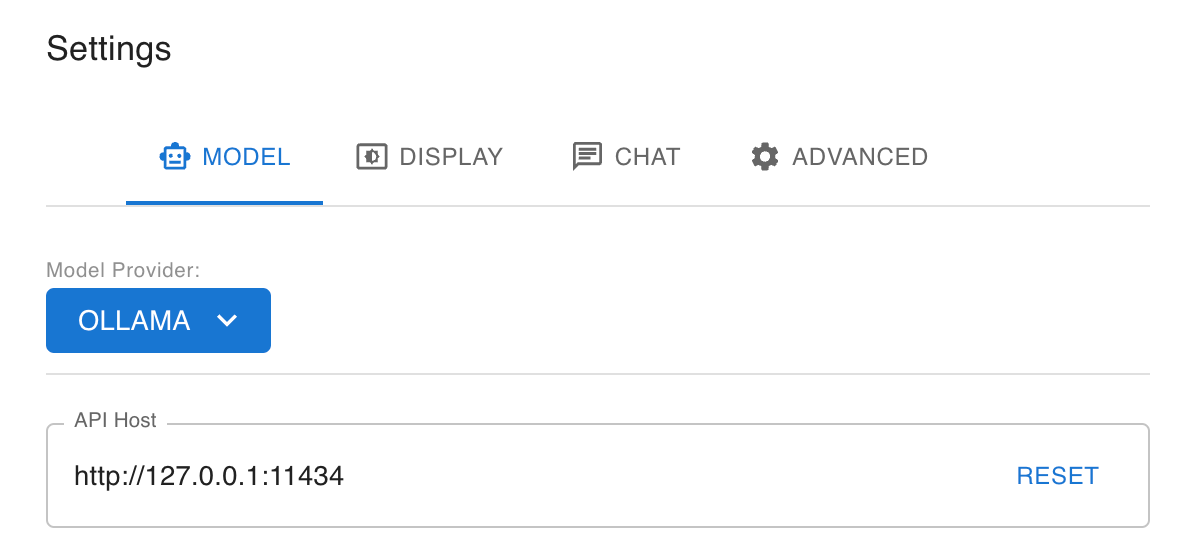
Once installed, open it and head to Settings and set your Model Provider to Ollama. It
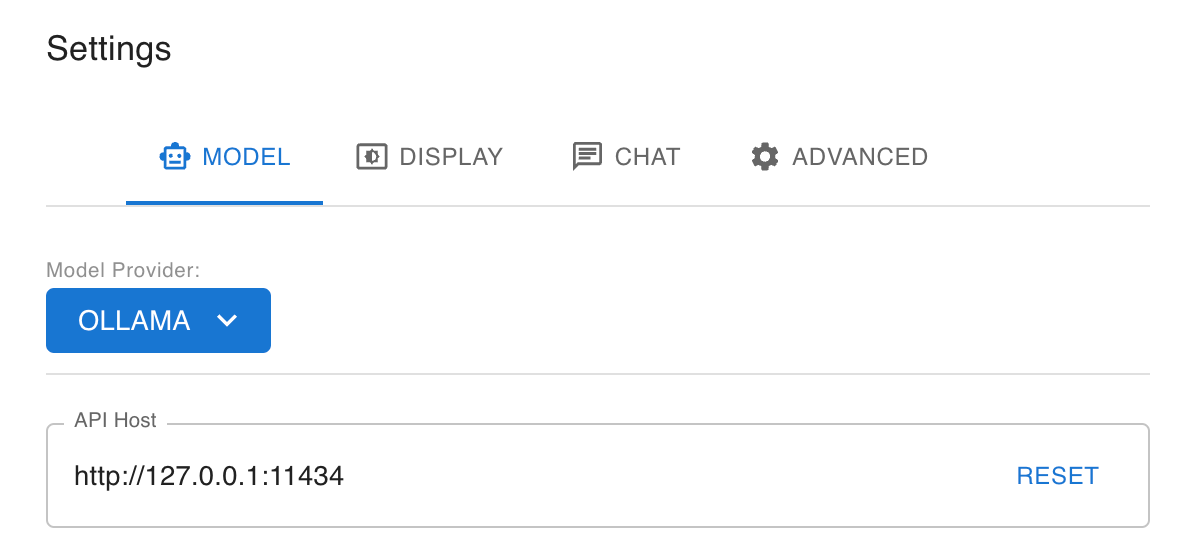
Ollama runs this API host by default, you shouldn’t have to change it. The UI is purposely similar to ChatGPT and should look nice and clean and familiar. It will format markdown, show images, code, and all the familiar things we’re used to. The only difference now is it’s all running on your laptop.


Step 4 (Advanced): HuggingFace
HuggingFace is one of the centers of the AI/ML universe. It’s a platform for engineers to collaborate, share, train new models, run new models, and all sorts of other things. Think of it like Github but for models and training.
The incredibly valuable thing about having open-source models like Meta’s Llama or DeepSeek’s R1 is that they can be modified, refined, and retrained all the time. On Ollama you only have access to the original DeepSeek versions of R1. But on HuggingFace right now, there are over 4,000 varieties. There are smaller versions for more speed, retrained versions to remove the censors, trained versions particularly good at creative writing, or at Japanese, or at coding. You can run any of these models too!
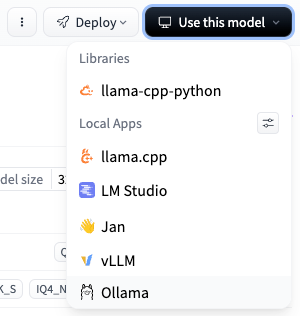
Find an interesting model on HuggingFace. Pretty much anything in a GGUF format will run in Ollama. We’re going to try this Ablated R1. Ablated means some of the human feedback has been removed so that it won’t refuse to answer prompts that could be rude or censored. The original R1 models would give hiccups when asked to describe the CCP in a negative way, but the ablated versions will give you the goods (open source for the win!)
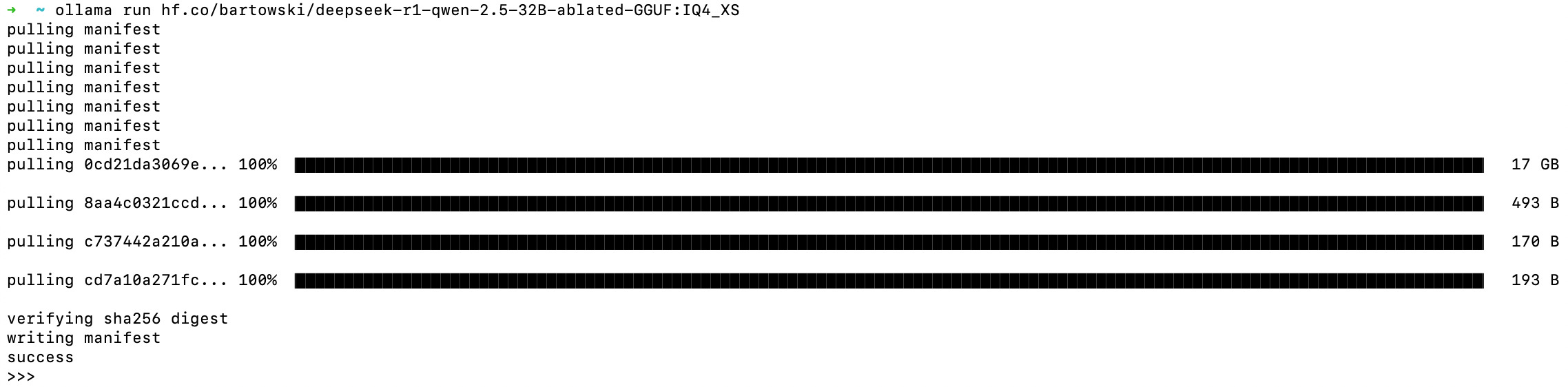
Check out the versions and find one that fits your constraints. In this case, I’m looking at IQ4_XS. About an 18 GB file. You’ll be able to select that version next. Hit “Use this model” and copy your command.
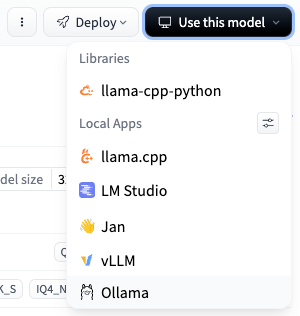
Run the command in your terminal and let that sucker download.

Give it a go! Depending on how you prompt, you’ll see some different answers!